

The scale of capital flowing into AI infrastructure has reached extraordinary levels. Collective hyperscaler spending in 2025—led by Amazon at approximately $125 billion, Alphabet at $91-93 billion, Microsoft at $80 billion, and Meta at $70-72 billion—represents capital allocation decisions without precedent in technology history, with industry projections placing cumulative AI investment in the trillions through 2030.
Within this spending tsunami, the Anthropic-Google partnership offers a clarifying data point. Anthropic's revenue grew from roughly $1 billion at the start of 2025 to approximately $7 billion in annualized run rate by October—a 7x increase in ten months driven by large enterprise accounts that grew sevenfold over the past year. The company chose to secure this growth with TPU infrastructure rather than Nvidia GPUs. For a company whose existence depends on compute economics, that choice carries signal.
The technical foundation for this decision lies in Google's custom silicon and interconnect architecture. The Ironwood TPU v7, announced in 2025, delivers 4.6 petaFLOPS of FP8 performance—marginally exceeding Nvidia's B200 at 4.5 petaFLOPS. But the more consequential specifications appear in scaling: Ironwood pods connect up to 9,216 chips through Google's proprietary optical interconnect, compared to 72 chips in Nvidia's NVL72 systems. That 128x advantage in single-domain connectivity directly addresses the memory bandwidth constraints that increasingly determine inference economics.
This scaling architecture rests on what may be Google's most underappreciated technical asset: Project Apollo, a decade-long investment in optical circuit switching. Traditional data center networks route data through electronic packet switches that convert optical signals to electrical, process routing decisions, then convert back to optical for transmission. Each conversion stage adds latency, cost, and power consumption. Google's approach bypasses this overhead in the network fabric. Using custom micro-electro-mechanical systems (MEMS) mirrors—non-blocking 136×136 optical circuit switches—Apollo routes optical signals directly from source to destination without intermediate electrical processing.
The infrastructure implications extend beyond raw performance metrics. According to Google's SIGCOMM 2022 paper, its Jupiter network—rebuilt around optical circuit switching—delivers 40% less power consumption, 30% lower cost, and 50x less downtime than conventional approaches. The mirrors themselves consume minimal power; they need only hold position, not actively switch. And because OCS is data-rate agnostic, the same physical infrastructure supports multiple generations of networking speeds without replacement.
This provides the foundation for Vahdat's doubling mandate. Achieving 1,000x capacity at constant cost and power requires exponential efficiency gains, not merely exponential spending. The optical switching architecture makes that trajectory at least technically plausible—each doubling leverages existing infrastructure rather than requiring proportional capital expansion.
The investment implications cut across multiple dimensions. First, the Anthropic deal demonstrates that efficiency advantages can attract revenue at scale—the ultimate test of any infrastructure investment thesis. If Google can deliver inference economics that improve with scale while competitors face diminishing returns, pricing dynamics across the entire AI services market shift accordingly.
Second, Vahdat's framing inverts how investors typically model capacity investments. Most infrastructure buildouts assume marginal cost stability or modest improvement. A doubling mandate at constant cost implies a marginal cost curve that declines by half every six months. If accurate, this creates both opportunity and risk: opportunity for services built on that cost curve, risk for competitors whose cost structures cannot match it.
The immediate question is whether this efficiency thesis extends beyond Google's captive workloads. Anthropic provides one external validation. The broader test will be whether Google Cloud can translate internal infrastructure advantages into competitive pricing that captures share from AWS and Azure—a market share battle that current spending levels suggest will be contested aggressively. Watch for Google Cloud's inference pricing relative to competitors over the next two quarters; that spread will reveal whether the optical moat translates to commercial advantage.
The efficiency thesis faces a vocal skeptic chorus. MIT economist Daron Acemoglu, awarded the 2024 Nobel Memorial Prize in Economic Sciences, warned in November 2025: "These models are being hyped up, and we're investing more than we should." Sparkline Capital's Kai Wu, in October 2025 research spanning a century of infrastructure cycles, calculates that current AI-native revenues of approximately $20 billion must grow 100-fold to justify projected spending—and finds that firms aggressively increasing capital expenditures subsequently underperform peers by 8.4% annually. Bain estimates that sustaining projected capex through 2030 requires $2 trillion in annual cloud and AI revenue, leaving an $800 billion shortfall after accounting for enterprise reinvestment.
These analyses share a common methodology: projecting future revenue requirements and finding current AI services wanting. What they uniformly overlook is the demand already under contract.
Google Cloud's backlog reached $155 billion in Q3 2025—up 46% quarter-over-quarter and 82% year-over-year. AWS reported approximately $200 billion in remaining performance obligations, with management noting that October deal volume alone exceeded total Q3 bookings. Combined, $355 billion in contracted cloud commitments represents revenue not yet recognized—signed agreements, not projections. Google Cloud signed more billion-dollar contracts in the first nine months of 2025 than in 2023 and 2024 combined. Over 70% of existing Google Cloud customers now purchase AI products. Revenue from products built on Google's generative models grew more than 200% year-over-year.
The demand signal extends to Google's largest infrastructure partner. Anthropic's revenue grew 7x in ten months—from roughly $1 billion to $7 billion in annualized run rate by October. Companies experiencing that growth trajectory do not commit "tens of billions" to TPU infrastructure because they received a discount. They commit because they need the capacity.
Alphabet CEO Sundar Pichai addressed capacity constraints directly at a November 6 internal meeting: "I actually think for how extraordinary the cloud numbers were, those numbers would have been much better if we had more compute." Regarding Google's video generation tool Veo, he added: "If we could've given it to more people, we would have gotten more users but we just couldn't because we are at a compute constraint." This is not the language of speculative overbuilding. It is the language of demand outstripping supply.
The skeptical framework conflates two distinct questions. The first—whether AI will generate sufficient revenue to justify total infrastructure investment across all participants—remains legitimately uncertain. The second—whether current hyperscaler spending is speculative supply-building ahead of demand—has a clearer answer in the backlog data. When customers have contractually committed $355 billion to cloud services, characterizing that spending as "building ahead of demand" misreads what the demand signal shows.
This does not invalidate all skeptic concerns. Contract conversion rates, margin compression risks, and demand concentration among frontier AI labs warrant monitoring. But the prevalent narrative—that hyperscalers are engaged in speculative capex wars—ignores that contracted demand already exceeds deliverable capacity. The constraint is physical infrastructure, not customer appetite.
The Signal and Noise converge on a common axis: the relationship between infrastructure investment and demand. Skeptics ask whether revenue can ever justify capex. The efficiency thesis asks whether capex can ever satisfy demand. The backlog data suggests the second question is more pressing than the first.
$355 billion in contracted cloud commitments did not materialize from marketing optimism. Google Cloud's backlog grew 82% year-over-year while revenue grew 34%—contracted demand is accelerating faster than current capacity can recognize it. AWS reported October deal volume exceeding its entire Q3 pipeline. When executives describe their businesses as "capacity constrained" rather than "demand constrained," the investment thesis shifts from speculative to execution-dependent.
The efficiency differentiation matters precisely here. Google's optical architecture, TPU scaling advantages, and generational efficiency gains determine how much contracted revenue can be converted to delivered service. Infrastructure providers solving physical constraints will capture disproportionate share of backlog conversion. Those building traditional architectures face longer timelines to revenue recognition—and greater exposure to margin compression as capacity eventually catches demand.
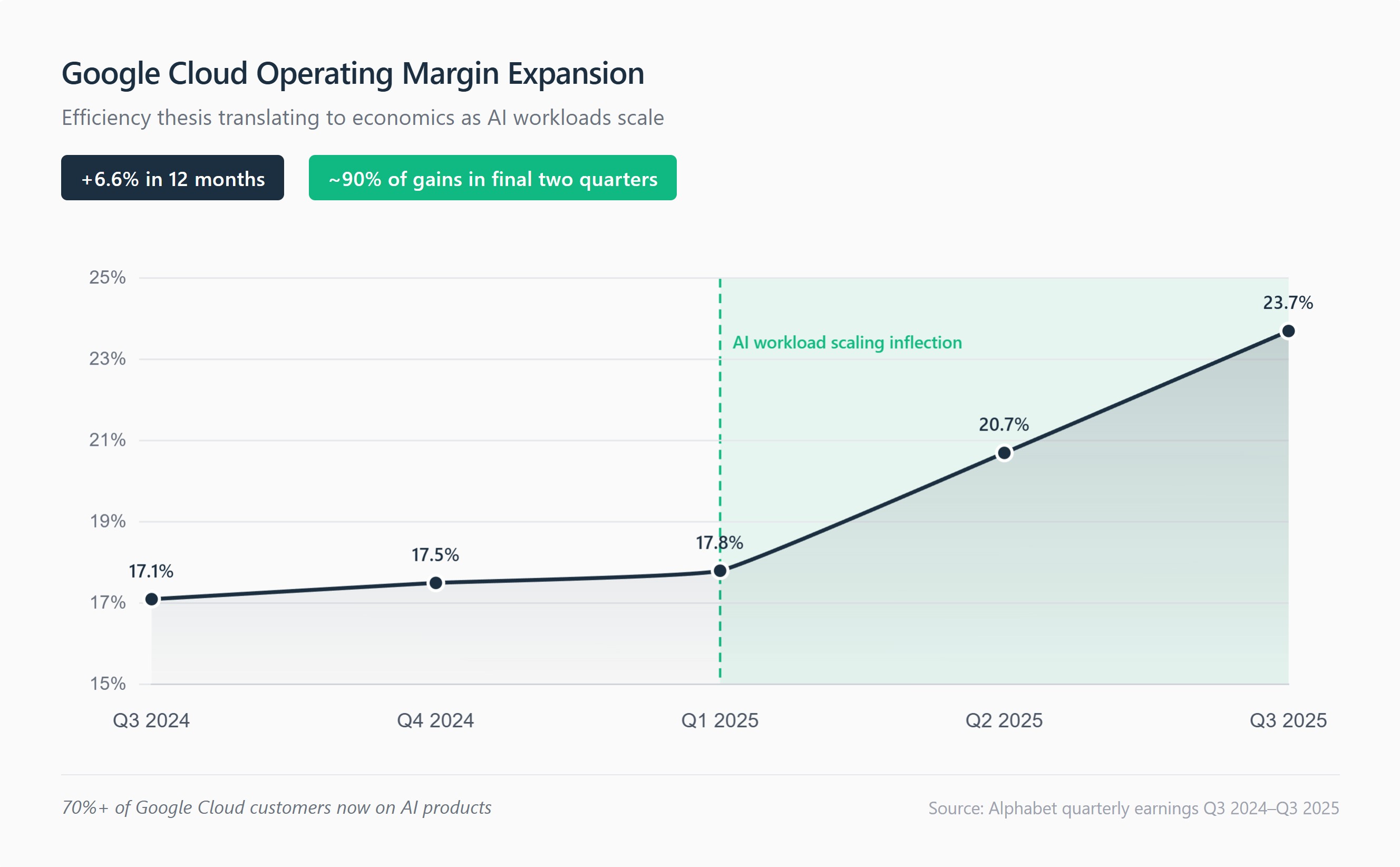
For portfolio positioning, monitor three metrics over the next four quarters. First, the ratio of backlog growth to capex growth: if backlog continues outpacing investment, demand is pulling infrastructure rather than infrastructure pushing supply. Second, Cloud operating margins as AI workload mix increases: efficiency advantages should manifest as margin resilience even with higher AI concentration. Third, billion-dollar deal velocity: the pace of large enterprise commitments reveals whether demand breadth matches demand depth.
The investment implication favors efficiency-advantaged hyperscalers over pure capex competitors. In the AI infrastructure buildout, following the demand signal means distinguishing between who is spending and who is spending efficiently.
The efficiency thesis warrants an elevated 8.2 rating based on three reinforcing validation layers. First, technical validation: Google's optical architecture is independently verifiable through academic papers (SIGCOMM 2022) and industry analysis, with documented 40% power and 30% cost advantages. Second, commercial validation: Anthropic's "tens of billions" TPU commitment—made explicitly for "price-performance and efficiency"—confirms these advantages translate to market competitiveness. Third, demand validation: $355 billion in contracted cloud backlog (Google $155B, AWS $200B) represents signed commitments, not projections, while Pichai's acknowledgment that revenue was constrained by compute availability inverts the speculative narrative.
The rating remains below 8.5 due to execution dependencies. Google's SIGCOMM research acknowledges optical switching advantages depend on "relatively predictable traffic patterns"—whether inference workloads qualify at scale remains unproven. Contract conversion timing and competitive response from Nvidia's ecosystem also introduce uncertainty. The thesis is **directionally correct, demand-validated, and investable** with clear monitoring metrics.
This commentary is provided for informational purposes only and does not constitute investment advice, an offer to sell, or a solicitation to buy any security. The information presented represents the opinions of The Stanley Laman Group as of the date of publication and is subject to change without notice.
The securities, strategies, and investment themes discussed may not be suitable for all investors. Investors should conduct their own research and due diligence and should seek the advice of a qualified investment advisor before making any investment decisions. The Stanley Laman Group and its affiliates may hold positions in securities mentioned in this commentary.
Past performance is not indicative of future results. All investments involve risk, including the potential loss of principal. Forward-looking statements, projections, and hypothetical scenarios are inherently uncertain and actual results may differ materially from expectations.
The information contained herein is believed to be accurate but is not guaranteed. Sources are cited where appropriate, but The Stanley Laman Group makes no representation as to the accuracy or completeness of third-party information.
This material may not be reproduced or distributed without the express written consent of The Stanley Laman Group.
© 2025 The Stanley-Laman Group, Ltd. All rights reserved.
SLG is an independent investment management and advisory firm serving ultra-high-net-worth individuals, families, and institutions.
